Geometric feature extraction is a crucial component of point cloud registration pipelines.
Recent work has demonstrated how supervised learning can be leveraged to learn better and more compact 3D features.
However, those approaches' reliance on ground-truth annotation limits their scalability.
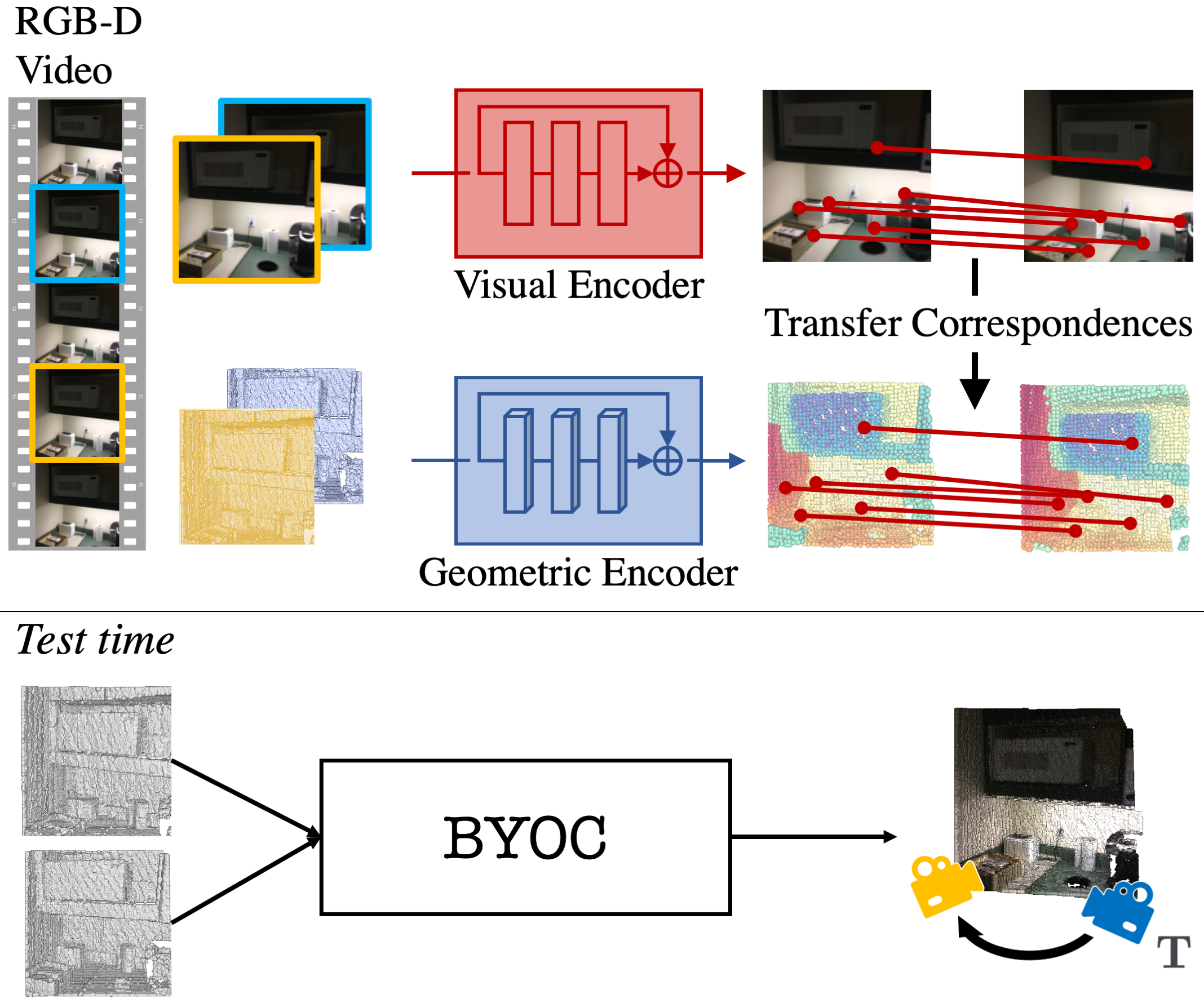
We propose BYOC: a self-supervised approach that learns visual and geometric features from RGB-D video without relying on ground-truth pose or correspondence.
Our key observation is that randomly-initialized CNNs readily provide us with good correspondences; allowing us to bootstrap the learning of both visual and geometric features.
Our approach combines classic ideas from point cloud registration with more recent representation learning approaches.
We evaluate our approach on indoor scene datasets and find that our method outperforms traditional and learned descriptors, while being competitive with current state-of-the-art supervised approaches.
We would like to thank Richard Higgins and Karan Desai for many helpful discussions and feedback on early drafts of this work.
This webpage template was borrowed from some colorful folks.