Aligning partial views of a scene into a single whole is essential to understanding one's environment and is a key component of numerous robotics tasks such as SLAM and SfM.
Recent approaches have proposed end-to-end systems that can outperform traditional methods by leveraging pose supervision.
However, with the rising prevalence of cameras with depth sensors, we can expect a new stream of raw RGB-D data without the annotations needed for supervision.
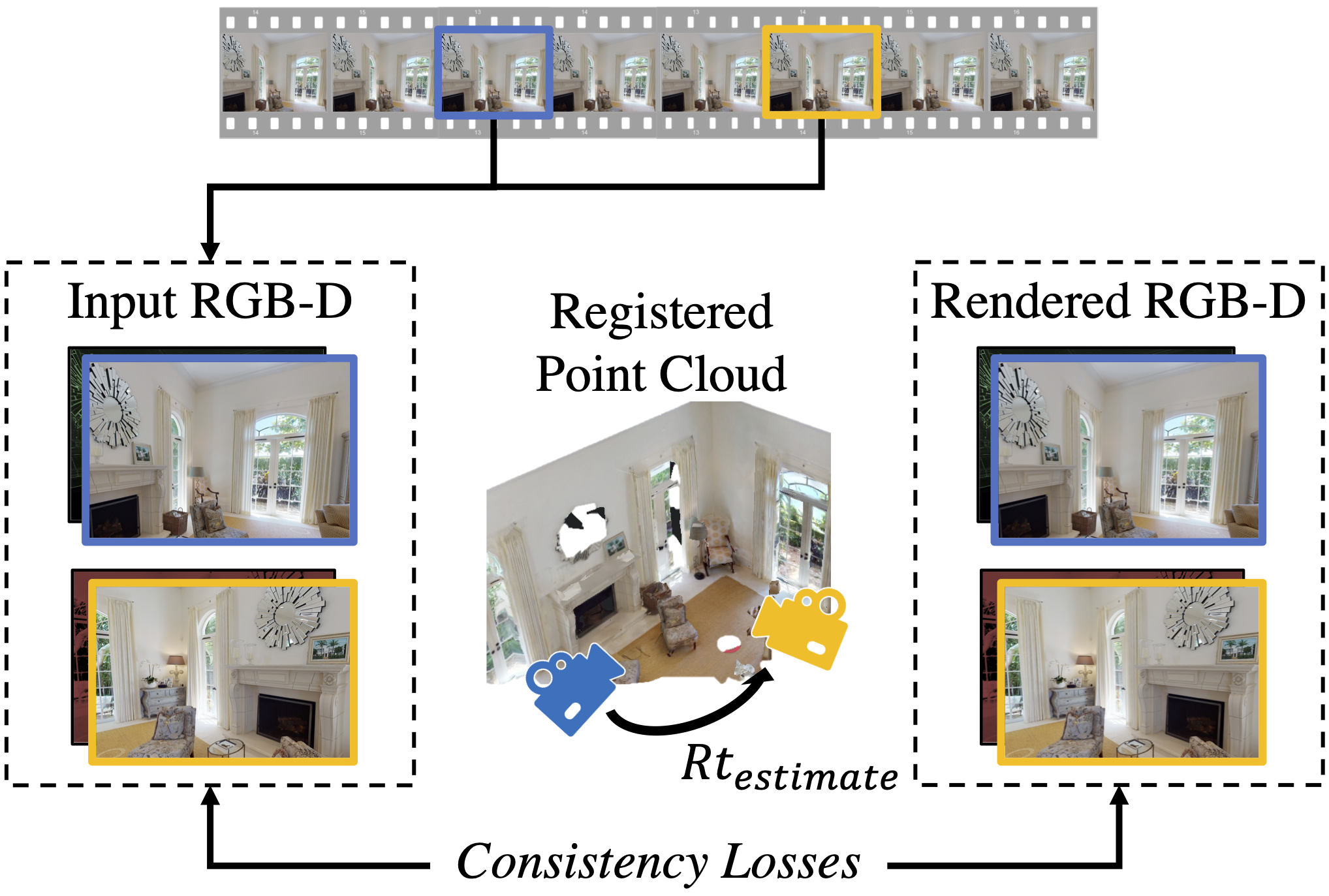
We propose UnsupervisedR&R: an end-to-end unsupervised approach to learning point cloud registration from raw RGB-D video.
The key idea is to leverage differentiable alignment and rendering to enforce photometric and geometric consistency between frames.
We evaluate our approach on indoor scene datasets and find that we outperform existing traditional approaches with classic and learned descriptors, while being competitive with supervised geometric point cloud registration approaches.
Overview Video
Paper
El Banani, M., Gao, L., and Johnson, J.
UnsupervisedR&R: Unsupervised Point Cloud Registration via Differentiable Rendering
We would like to thank the anonymous re-viewers for their valuable comments and suggestions.
We also thank Nilesh Kulkarni, Karan Desai, Richard Higgins, and Max Smith for many helpful discussions and feedback on early drafts of this work.
This webpage template was borrowed from some colorful folks.